Artificial Intelligence is seeing massive adoption in several industries like finance, digital marketing, e-commerce, and healthcare. There’s no denying that AI is here to stay, and some jobs are already in danger of being replaced by computer code. But for all its benefits, AI still has a few massive hurdles to overcome before becoming its best iteration. Here are two challenges that AI is facing right now.
Computing Power And Energy Requirements
It’s no surprise that AI requires a lot of computer power and needs more if we want to develop it further. However, the current state of computing might not be proportionate to AI’s projected growth requirements.
Moore’s Law is Dying
Computers have developed so much over the last few years that Moore’s Law, a foundational principle in the advancement of computer science since its inception in 1965, is becoming obsolete. As a refresher, Moore’s Law states that transistors in a microchip will double roughly every two years, meaning we can expect a doubling of computing performance every two years while the cost of computers is reduced. This law has been held for almost 60 years, but the computer industry will soon run against a wall.
Sure, we’ve seen the development from 14-nanometer (nm) to 7-nanometer transistors in the past decade, while 5nm and 3nm chips are already being used in specific industries. Chip manufacturers are now working on 2nm transistors, slated to be released in 2024. Now those are incredibly tiny transistors; for context, DNA molecules are 2.5nm wide. If we want to keep up with Moore’s law, we’ll soon have to manufacture transistors closer to an atom’s size (0.1 to 0.5nm). AI needs further investment in this particular segment to sustain its growth.
Power And The Demand for AI
Many industries are integrating AI into their workflows and processes. Businesses like social media, customer service, analytics, and data security already see marked improvements using automated models. Specific tasks like healthcare diagnostics, communications, and even content creation are reaping the benefits of AI. Even heavily utilized tech like GPS — which was functionally complete even back in 1978 when the prototype satellite was first launched — is getting improved by AI with additions like tagging road features and generating imagery even through obstructions. But with widespread adoption comes the increased demand for power.
As developers continue to train AI with more and larger data sets with increased parameters, and as businesses continue to expand their use of AI, the demand for more energy grows. And with growing energy demands and consumption comes more carbon emissions. To put things into perspective, OpenAI’s flagship generative AI, ChatGPT, is estimated to consume 1 gigawatt-hour (GWh) daily. This roughly equals the power consumed by 33,000 U.S. homes in the same period.
…And Then There’s The Cost
A recent report by The Wall Street Journal stated that Microsoft, one of the world’s leading AI development companies, is losing money in its GitHub Copilot subscription model. The program was developed with OpenAI to assist programmers using Visual Studio Code, Visual Studio, Neovim, and JetBrains. Right now, Copilot is $10 per month. However, subscribers have been extensively utilizing the tool, costing Microsoft $20 per month on average to provide the service. Some power users have even been noted to cost the company $80 monthly!
Now, onto the biggest name in the AI industry. Despite the widespread use of ChatGPT, we still don’t know if OpenAI is profitable, although it has seen a massive revenue bump since it started charging companies for using and integrating the large-language model (LLM) chatbot into their production process. Back in 2022, the company was $540 million in the hole. But this year, some sources estimate that the company is earning about $80 million per month, bringing its potential annual earnings near $1 billion.
But, again, we still don’t have concrete numbers. AI companies must balance cost, consumption, and results to make their businesses more sustainable.
Bias
To explain the issue of AI bias, let’s take a closer look at how it manages to think. Machine learning (ML) is the core foundation of AI, and there are two main ways of doing that.
Supervised Learning
Supervised learning is the technique that uses labeled data or data with information tags or meta-data like classification, properties, characteristics, and other valuable elements. The AI is also presented with a list of outcomes or output labels. Using its base programming and some routine adjustments done by human supervisors, the AI maps the relationship between input and outcome. The new way of “thinking” the AI learned is applied to future data sets and tasks.
For a quick analogy, imagine a teacher discussing long division with a student. The student is given instructions on how to do it and the eventual correct answer. As the student progresses and makes mistakes, the teacher gives corrections and guidance until they arrive at the correct answer. This is all good if the teacher does a perfect job, but mistakes can happen. If that’s the case, the student will use and perpetuate any mistakes learned from the process until someone corrects them, but we’ll get into that later.
To make the explanation easier, let’s do another simple example. Let’s say that we want an AI program to take a picture of miscellaneous fruits (data set) and identify which ones are apples, oranges, and blueberries (output labels) and how many of which there are. The process will look something like this:
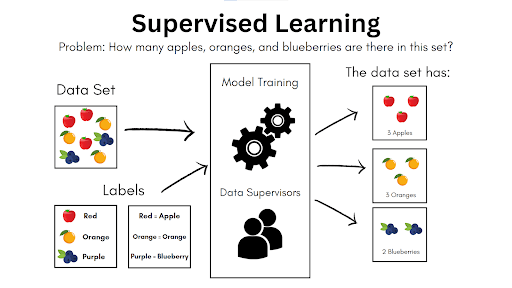
Using two sets of labels, the AI can identify which ones are apples, oranges, and blueberries. The characteristics used to group these data are then stored in the programming to be used for future similar tasks. Again, this is a simplified representation: if you want a solid idea of how AI does this, you can multiply the data set by a couple of billion times. Supervised learning is used primarily for large-scale data classification and creating predictive models.
Unsupervised Learning
The second machine learning technique is unsupervised learning. The AI is presented with an unlabeled data set and tasked with identifying the details that differentiate each of them while simultaneously identifying common factors. If we take the previous example, it will look something like this:
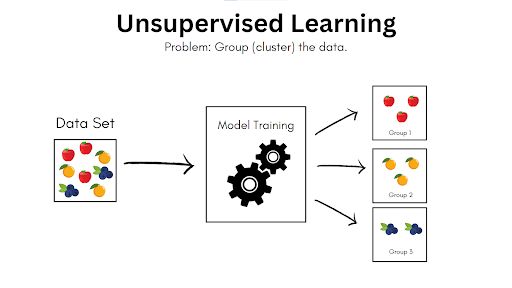
As indicated, unsupervised learning is excellent for grouping or clustering data, dimensionality reduction (reducing the features of data inputs as much as possible while retaining most of the original information relevant to the task required to make them easier to parse, like making a 3-D object into a 2-D object but keeping the same outline for easier classification), and probability density estimation (extrapolating total population numbers using random samples.) Regardless of the learning process, AI can provide strategic advantages to any business, ranging from improved predictive financial models to risk assessment automation.
The Potential Impact of Biases
So, how does all this connect to AI bias? Let’s take the supervised learning example and add another label: apples = bad. The AI will still group the data as usual, but with the added outcome that Group 1 is, for whatever reason, bad. The program will take this way of thinking and apply it to other data sets. It all seems inconsequential if we use fruits as an example. But imagine if the data were groups of people, and the model training is used to decide the best way to allocate scarce resources — or to choose which ones to save in the event of a global natural disaster.
But let’s move away from apocalyptic scenarios and discuss some potential, near-term implications of AI bias.
- Discrimination in Hiring: Biased AI-based hiring systems may discriminate against certain groups based on gender, race, or other protected attributes. For example, if historical hiring data is biased, the AI system may perpetuate and amplify those biases, resulting in unfair hiring practices. There have been some cases where something as simple as including the words “capture” and “arrest” have precluded potential candidates from automated hiring processes.
- Unfair Criminal Justice Predictions: Remember that early 2000s film Minority Report? Well, having an FBI Precrime Division is closer to reality than it ever was. However, using predictive analytics and automated risk assessment tools for police action may be affected by bias. Any historical data fed into the AI that contains skewed numbers towards certain minority groups may lead to their unfair targeting.
- Healthcare Issues: Biases in AI healthcare applications can lead to disparities in treatment recommendations. In the 1990s, there were several incorrect diagnoses of breast cancer based on X-rays, leading to unnecessary treatments and expenses, not to mention the devastating mental toll of being told you have cancer. Imagine having these incorrect assumptions and diagnostic practices plugged into AI systems. Imagine having incorrect assumptions and diagnostic practices for every disease known to man. It’s enough to give any doctor nightmares.
Unfortunately, machine learning bias doesn’t just come from data or training labels. The base algorithm may have inherent biases, reinforcement training can start or strengthen identified objectivity issues, and population data may be incomplete or have underrepresented groups, potentially creating lopsided results in favor of other represented groups.
Conclusion
The difficulties AI companies face aren’t things you could simply brush aside, as they can potentially have massive ramifications for other companies utilizing the technology. These weaknesses can be slightly mitigated in several ways, although not all of them can be done outside of development. So far, all we can do is wait and see how things will play out and hope that the fixes come sooner rather than later.


